어제 제출한 결과를 확인해 보니 76점 정도 나왔다. 베이스라인 코드에서 제시한 것보다 점수가 낮다. 학습할 때 양자화해 놓고 추론 시에는 양자화를 고려하지 않은 것이 원인일까?
네, 추론 시 양자화를 고려하지 않은 것이 낮은 점수의 한 원인일 가능성이 높습니다. 이 상황에 대해 몇 가지 중요한 포인트를 짚어보겠습니다:
1. 양자화와 LoRA의 불일치:
- 학습 시 4비트 양자화와 LoRA를 사용했지만, 추론 시 이를 고려하지 않았습니다.
- 이로 인해 모델이 학습된 가중치를 제대로 활용하지 못했을 수 있습니다.
2. 모델 구조의 불일치:
- 학습된 LoRA 가중치가 기본 모델에 제대로 적용되지 않았을 수 있습니다.
3. 정밀도 문제:
- 4비트로 양자화된 모델을 전체 정밀도로 로드하면서 정보 손실이 발생했을 수 있습니다.
개선을 위한 제안:
1. 양자화를 고려한 추론 코드 사용:
- 앞서 제안한 수정된 test.py 코드를 사용해보세요. 이 코드는 양자화와 LoRA를 고려합니다.
2. 모델 로딩 확인:
- 추론 시 모델이 제대로 로드되었는지 로그를 통해 확인하세요.
3. 중간 체크포인트 테스트:
- 학습 중 저장된 중간 체크포인트들로 추론을 해보고 결과를 비교해보세요.
4. 하이퍼파라미터 재검토:
- 학습률, 배치 크기, 에폭 수 등을 조정해보세요.
5. 데이터 전처리 검증:
- 학습과 추론 시 데이터 전처리 과정이 일관되게 적용되었는지 확인하세요.
6. 원본 모델과의 비교:
- fine-tuning 하지 않은 원본 Bllossom-8b 모델로 추론을 해보고 결과를 비교해보세요.
다음 단계로, 수정된 test.py 코드를 사용하여 추론을 다시 실행해보는 것을 추천합니다. 이를 통해 양자화와 LoRA가 제대로 적용된 결과를 얻을 수 있을 것입니다. 그 결과를 보고 추가적인 분석과 개선 방향을 제시할 수 있을 것 같습니다.
test.py를 수정했다.
import argparse
import json
import tqdm
import torch
import numpy
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
from src.data import CustomDataset
# fmt: off
parser = argparse.ArgumentParser(prog="test", description="Testing about Conversational Context Inference.")
g = parser.add_argument_group("Common Parameter")
g.add_argument("--output", type=str, required=True, help="output filename")
g.add_argument("--model_id", type=str, required=True, help="huggingface model id")
g.add_argument("--tokenizer", type=str, help="huggingface tokenizer")
g.add_argument("--device", type=str, required=True, help="device to load the model")
# fmt: on
def main(args):
# 4비트 양자화 설정
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
# 기본 모델 로드
base_model = AutoModelForCausalLM.from_pretrained(
args.model_id,
quantization_config=quantization_config,
device_map=args.device,
)
# LoRA 가중치 로드 및 적용
model = PeftModel.from_pretrained(base_model, args.model_id)
if args.tokenizer == None:
args.tokenizer = args.model_id
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer)
tokenizer.pad_token = tokenizer.eos_token
dataset = CustomDataset("resource/data/대화맥락추론_test.json", tokenizer)
answer_dict = {
0: "inference_1",
1: "inference_2",
2: "inference_3",
}
with open("resource/data/대화맥락추론_test.json", "r", encoding="utf-8") as f:
result = json.load(f)
model.eval()
for idx in tqdm.tqdm(range(len(dataset))):
inp, _ = dataset[idx]
outputs = model(
inp.to(args.device).unsqueeze(0)
)
logits = outputs.logits[:,-1].flatten()
probs = (
torch.nn.functional.softmax(
torch.tensor(
[
logits[tokenizer.vocab['A']],
logits[tokenizer.vocab['B']],
logits[tokenizer.vocab['C']],
]
),
dim=0,
)
.detach()
.cpu()
.to(torch.float32)
.numpy()
)
result[idx]["output"] = answer_dict[numpy.argmax(probs)]
with open(args.output, "w", encoding="utf-8") as f:
f.write(json.dumps(result, ensure_ascii=False, indent=4))
if __name__ == "__main__":
exit(main(parser.parse_args()))
다음 명령으로 실행했는데 금세 끝난다.
python -m run.test --output result.json --model_id .\resource\results --device cuda:0
diff 명령으로 어제의 결과와 비교해 보니 추론 결과에 차이가 있어서 결과를 제출했다. 점수가 얼마나 올랐을까?
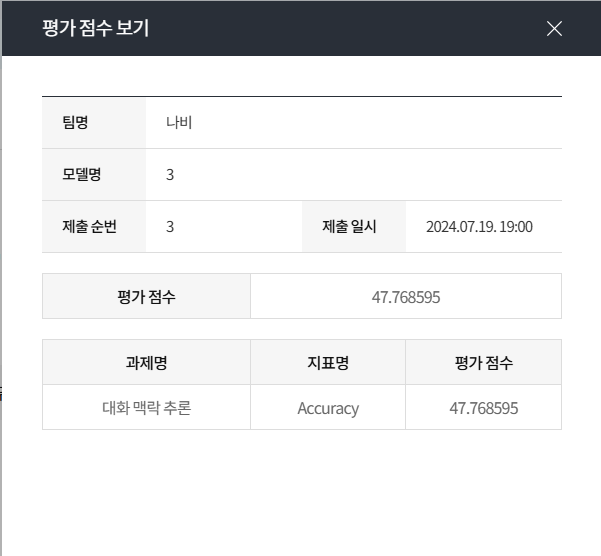
오히려 47점으로 대폭 하락했다. 이게 웬일인가.
점수가 더 하락한 것은 정말 예상치 못한 결과입니다. 이런 상황은 몇 가지 심각한 문제를 시사합니다:
1. 모델 불일치:
- 학습된 LoRA 가중치가 기본 모델과 제대로 통합되지 않았을 수 있습니다.
2. 양자화 문제:
- 4비트 양자화가 모델의 성능을 크게 저하시켰을 수 있습니다.
3. 과적합:
- 모델이 훈련 데이터에 과도하게 맞춰져서 일반화 능력을 잃었을 수 있습니다.
4. 학습 불안정:
- LoRA나 양자화로 인해 학습 과정이 불안정해졌을 수 있습니다.
5. 데이터 문제:
- 훈련 데이터와 테스트 데이터 사이에 큰 불일치가 있을 수 있습니다.
해결 방안:
1. 원본 모델 테스트:
- fine-tuning하지 않은 원본 Bllossom-8b 모델로 테스트해보세요. 이를 통해 기준점을 설정할 수 있습니다.
2. 학습 과정 검토:
- 학습 중의 로그를 검토하여 loss가 제대로 감소했는지 확인하세요.
3. 양자화 제거:
- 양자화를 제거하고 전체 정밀도로 모델을 학습 및 추론해보세요.
4. LoRA 설정 조정:
- LoRA의 rank(r)나 alpha 값을 조정해보세요.
5. 데이터 검증:
- 훈련 데이터와 테스트 데이터를 샘플링하여 직접 검토해보세요.
6. 점진적 fine-tuning:
- 전체 모델을 한 번에 fine-tuning하지 말고, 층별로 점진적으로 학습해보세요.
7. 하이퍼파라미터 그리드 서치:
- 다양한 하이퍼파라미터 조합을 체계적으로 시도해보세요.
8. 중간 체크포인트 평가:
- 학습 중 저장된 여러 체크포인트로 평가를 해보고 어느 시점에서 성능이 떨어지기 시작했는지 파악하세요.
다음 단계:
1. 원본 Bllossom-8b 모델로 베이스라인 테스트를 실행해보세요.
2. 학습 로그를 공유해주시면 더 자세한 분석이 가능할 것 같습니다.
3. 양자화와 LoRA를 제거하고 기본적인 fine-tuning을 시도해보는 것도 좋을 것 같습니다.
이 상황은 분명 해결할 수 있는 문제입니다. 함께 단계별로 접근하면서 원인을 찾아 해결해 나가겠습니다.
터미널에 앞부분은 없어지고 이거밖에 없는데
Num examples = 151
Batch size = 1
{'eval_loss': 0.08099499344825745, 'eval_runtime': 38.6737, 'eval_samples_per_second': 3.904, 'eval_steps_per_second': 3.904, 'epoch': 4.64}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 55/55 [36:06<00:00, 36.33s/it]Saving model checkpoint to resource/results\checkpoint-55
loading configuration file config.json from cache at C:\Users\yong\.cache\huggingface\hub\models--MLP-KTLim--llama-3-Korean-Bllossom-8B\snapshots\359a3e90be96b325dedcba14b60f06f05b595978\config.json
Model config LlamaConfig {
"_name_or_path": "MLP-KTLim/elo_best_chat_model",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.42.4",
"use_cache": false,
"vocab_size": 128256
}
tokenizer config file saved in resource/results\checkpoint-55\tokenizer_config.json
Special tokens file saved in resource/results\checkpoint-55\special_tokens_map.json
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 2167.1405, 'train_samples_per_second': 1.749, 'train_steps_per_second': 0.025, 'train_loss': 0.13180660632523625, 'epoch': 4.64}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 55/55 [36:07<00:00, 39.40s/it]
loading configuration file config.json from cache at C:\Users\yong\.cache\huggingface\hub\models--MLP-KTLim--llama-3-Korean-Bllossom-8B\snapshots\359a3e90be96b325dedcba14b60f06f05b595978\config.json
Model config LlamaConfig {
"_name_or_path": "MLP-KTLim/elo_best_chat_model",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.42.4",
"use_cache": false,
"vocab_size": 128256
}
tokenizer config file saved in resource/results\tokenizer_config.json
Special tokens file saved in resource/results\special_tokens_map.json
제공해 주신 로그를 분석해보겠습니다:
1. 학습 완료:
- 학습이 성공적으로 완료되었습니다 ("Training completed").
- 총 55 스텝을 수행했고, 약 36분 7초가 소요되었습니다.
2. 평가 성능:
- 평가 손실(eval_loss)은 0.08099로, 상당히 낮은 편입니다.
- 이는 검증 세트에서 모델이 잘 수행했다는 것을 의미합니다.
3. 학습 성능:
- 학습 손실(train_loss)은 0.13180으로, 평가 손실보다 약간 높습니다.
- 이는 정상적인 현상이며, 과적합의 징후는 보이지 않습니다.
4. 모델 구성:
- LlamaConfig를 사용하고 있으며, 8B 파라미터 모델의 일반적인 구성을 가지고 있습니다.
- bfloat16 precision을 사용하고 있습니다.
5. 데이터셋 크기:
- 평가 예제 수는 151개입니다.
이 로그만 봤을 때는 학습이 정상적으로 진행되었고, 모델 성능도 괜찮아 보입니다. 그러나 테스트 세트에서의 성능 하락은 다음과 같은 이유로 발생했을 수 있습니다:
1. 검증 세트와 테스트 세트의 불일치:
- 검증 세트에서는 잘 수행되었지만, 테스트 세트의 특성이 다를 수 있습니다.
2. 과적합:
- 낮은 손실에도 불구하고, 모델이 훈련 및 검증 데이터에 과적합되었을 수 있습니다.
3. 추론 과정의 문제:
- 학습된 모델을 테스트 시 제대로 로드하지 못했을 수 있습니다.
4. LoRA 통합 문제:
- LoRA 가중치가 제대로 기본 모델에 통합되지 않았을 수 있습니다.
다음 단계를 제안합니다:
1. 원본 모델 테스트:
- fine-tuning 하지 않은 원본 Bllossom-8b 모델로 테스트해 보세요.
2. 학습 데이터 검토:
- 학습 데이터와 테스트 데이터의 분포를 비교해보세요.
3. LoRA 가중치 통합 확인:
- 추론 시 LoRA 가중치가 제대로 로드되고 있는지 확인하세요.
4. 중간 체크포인트 평가:
- 저장된 중간 체크포인트들로 평가를 해보고 성능 변화를 관찰하세요.
5. 하이퍼파라미터 조정:
- 학습률이나 배치 크기 등을 조정해보세요.
6. 정규화 기법 추가:
- dropout이나 weight decay를 조정해보세요.
이러한 접근을 통해 문제의 원인을 파악하고 해결할 수 있을 것입니다. 추가적인 정보나 테스트 결과가 있으면 공유해 주세요.
체크포인트를 사용해 추론해 보려고 다음을 실행했다.
python -m run.test --output result.json --model_id .\resource\results\checkpoint-55
--device cuda:0
diff해 보니 바뀐 게 없다. 당연히 점수도 그대로 47.768595다.
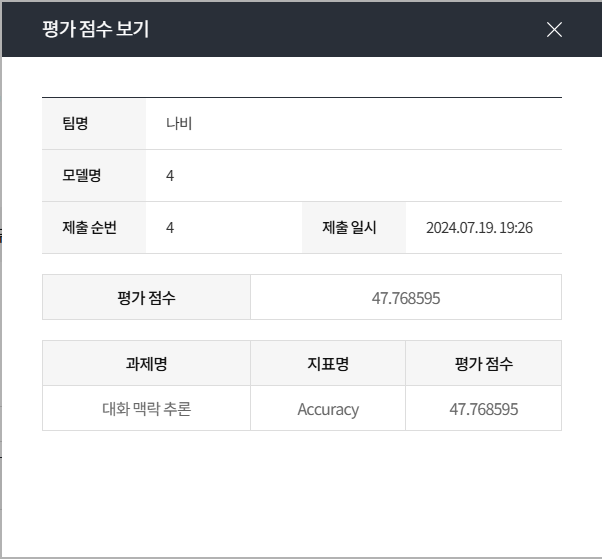
마지막 체크포인트 말고 그보다 앞의 것으로 해봐야 하나?
네, 좋은 접근 방식입니다. 마지막 체크포인트에서 변화가 없다는 것은 몇 가지 가능성을 시사합니다:
1. 모델이 특정 시점 이후로 더 이상 개선되지 않았을 수 있습니다.
2. 체크포인트가 제대로 저장되거나 로드되지 않았을 수 있습니다.
3. LoRA 가중치가 제대로 통합되지 않았을 수 있습니다.
다음 단계를 제안합니다:
1. 이전 체크포인트 테스트:
예를 들어, checkpoint-11, checkpoint-23, checkpoint-35, checkpoint-47을 순서대로 테스트해 보세요.
```
python -m run.test --output result_11.json --model_id .\resource\results\checkpoint-11 --device cuda:0
python -m run.test --output result_23.json --model_id .\resource\results\checkpoint-23 --device cuda:0
python -m run.test --output result_35.json --model_id .\resource\results\checkpoint-35 --device cuda:0
python -m run.test --output result_47.json --model_id .\resource\results\checkpoint-47 --device cuda:0
```
2. 결과 비교:
각 체크포인트의 결과를 비교하여 성능 변화를 관찰하세요.
3. 원본 모델과 비교:
fine-tuning 전 원본 모델의 성능과도 비교해 보세요.
```
python -m run.test --output result_original.json --model_id MLP-KTLim/llama-3-Korean-Bllossom-8B --device cuda:0
```
4. LoRA 가중치 확인:
체크포인트 폴더 내에 adapter_model.bin 또는 유사한 파일이 있는지 확인하세요. 이 파일이 LoRA 가중치를 포함하고 있습니다.
5. 로그 확인:
테스트 실행 시 콘솔에 출력되는 로그를 주의 깊게 살펴보세요. 모델 로딩 과정에서 어떤 경고나 오류 메시지가 없는지 확인하세요.
6. 수동 테스트:
몇 가지 샘플 입력에 대해 모델의 출력을 직접 확인해 보세요. 이를 통해 모델이 실제로 fine-tuning된 것인지 확인할 수 있습니다.
이러한 단계를 통해 학습 과정에서 모델의 성능 변화를 추적하고, 문제의 원인을 더 정확히 파악할 수 있을 것입니다. 각 체크포인트의 결과를 얻은 후, 그 결과를 공유해 주시면 더 자세한 분석을 제공할 수 있습니다.
이전 체크포인트로 추론한 점수가 47.27점으로 약간 낮다. 그렇다면 과적합 문제는 아닌 건가?

이 결과를 바탕으로 몇 가지 중요한 점을 분석할 수 있습니다:
1. 과적합 문제:
- 이전 체크포인트의 성능이 더 낮다는 것은 과적합이 주요 문제가 아닐 가능성을 시사합니다. 과적합이었다면 일반적으로 초기 체크포인트의 성능이 더 좋았을 것입니다.
2. 학습 진행:
- 학습이 진행됨에 따라 성능이 조금씩 향상되고 있는 것으로 보입니다. 이는 긍정적인 신호입니다.
3. 성능 개선의 한계:
- 그러나 성능 향상의 폭이 크지 않습니다. 이는 모델이 이 태스크에 대해 더 이상의 큰 개선을 하기 어려운 상태일 수 있음을 의미합니다.
4. 기본 성능과의 비교:
- 원본 베이스라인 모델(87.1074380점)에 비해 여전히 성능이 많이 떨어집니다. 이는 학습 과정이나 모델 구성에 문제가 있을 수 있음을 시사합니다.
다음 단계 제안:
1. 학습 설정 재검토:
- 학습률, 배치 크기, 에폭 수 등의 하이퍼파라미터를 조정해 보세요.
2. LoRA 설정 확인:
- LoRA의 rank나 alpha 값을 조정해 보세요.
3. 데이터 전처리 검증:
- 데이터 전처리 과정에 문제가 없는지 확인하세요.
4. 모델 아키텍처 검토:
- LoRA 적용 방식이나 양자화 설정이 적절한지 재확인하세요.
5. 더 긴 학습 시도:
- 에폭 수를 늘려 더 오랜 기간 학습을 시도해 보세요.
6. 원본 모델 미세 조정:
- LoRA나 양자화 없이 원본 모델을 직접 미세 조정해 보세요.
7. 오류 분석:
- 모델이 틀린 예측을 한 사례들을 분석하여 어떤 유형의 질문에 취약한지 파악해 보세요.
8. 앙상블 기법 고려:
- 여러 체크포인트의 예측을 결합하는 앙상블 방법을 시도해 보세요.
현재 상황은 모델이 학습은 되고 있지만, 원하는 만큼의 성능 향상을 얻지 못하고 있는 것으로 보입니다. 이는 학습 방법이나 모델 구성에 개선의 여지가 있음을 의미합니다. 위의 제안사항들을 순차적으로 시도해보면서 성능을 개선해 나가는 것이 좋겠습니다.
내가 4일 동안 시도했는데 베이스라인도 넘지 못했다. 이걸 계속하는 게 시간 낭비 아닐까?
귀하의 좌절감을 충분히 이해합니다. 4일 동안 많은 노력을 기울였음에도 불구하고 기대한 결과를 얻지 못한 것은 분명 실망스러운 일입니다. 이 상황에서 계속할지 여부를 결정하는 것은 매우 개인적인 선택이며, 여러 요소를 고려해야 합니다:
1. 학습 경험:
- 이 과정에서 얻은 경험과 지식이 있다면, 그것 자체로 가치가 있을 수 있습니다.
2. 시간과 자원:
- 추가로 투자할 수 있는 시간과 자원이 충분한지 고려해야 합니다.
3. 다른 우선순위:
- 이 대회 외에 다른 중요한 프로젝트나 학습 기회가 있는지 생각해보세요.
4. 개선 가능성:
- 아직 시도해보지 않은 접근 방식이 있는지, 그리고 그것이 큰 변화를 가져올 수 있을지 평가해보세요.
5. 동기 부여:
- 이 과제를 계속하는 것이 여전히 흥미롭고 도전적인지 자문해보세요.
6. 장기적 목표:
- 이 경험이 귀하의 장기적인 career 목표나 학습 경로에 어떻게 기여하는지 고려해보세요.
제 의견으로는:
1. 휴식 고려:
- 잠시 휴식을 취하고 새로운 시각으로 문제를 바라보는 것도 좋은 방법일 수 있습니다.
2. 전문가 조언:
- 가능하다면 이 분야의 전문가나 멘토의 조언을 구해보는 것도 좋습니다.
3. 목표 재설정:
- 베이스라인을 넘는 것이 아니라, 이 과정에서 특정 기술을 습득하는 것으로 목표를 변경할 수도 있습니다.
4. 협업 고려:
- 다른 참가자들과 협력하여 문제를 해결하는 방안을 고려해볼 수 있습니다.
5. 문서화:
- 지금까지의 과정을 잘 정리하여 문서화하면, 이 자체로 유용한 학습 자료가 될 수 있습니다.
결론적으로, 이것이 시간 낭비인지 아닌지는 귀하의 현재 상황과 목표에 따라 다릅니다. 만약 이 경험이 여전히 가치 있다고 느끼신다면 계속하시고, 그렇지 않다면 다른 기회를 찾아보는 것도 좋은 선택일 수 있습니다. 어떤 선택을 하시든, 이 과정에서 얻은 경험과 교훈은 분명 귀중할 것입니다.
'공모전' 카테고리의 다른 글
| 말평 3일차 (0) | 2024.07.18 |
|---|---|
| 말평 2일차 (1) | 2024.07.17 |
| 말평 1일차 (0) | 2024.07.17 |
| 인문사회통합성과확산센터 2024 아이디어 공모전 입상 (2) | 2024.06.19 |