공모전 및 경진대회 정보를 조사하다가 국립국어원에서 개최하는 ‘말평’ 경진대회를 알게 됐다.
지난 1학기에 머신러닝 과목을 수강하면서 캐글 대회에 참가했고, 얼마 전 챗GPT 활용 아이디어 공모전에도 나가 봤으니, 이제 전공 및 관심 분야에 좀 더 가까운 대회에 나가보면 좋겠다고 생각하던 참이었다.
게다가 때마침 직장의 이번주 업무가 허깅페이스 책을 교정하는 것이라, 경진대회에 참가하면서 책으로 배우면 내 공부도 되고 책 저자에게 더 좋은 피드백도 줄 수 있어 시너지 효과가 크겠다는 판단을 했다.
현재 열려 있는 과제 중 ‘대화 맥락 추론(가 유형)’을 선택했다.
https://kli.korean.go.kr/benchmark/taskOrdtm/taskList.do?taskOrdtmId=144
기준 모델: https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B
코드: https://github.com/teddysum/Korean_CCI_2024
무엇을 어찌해야 할지 통 모르겠어서 Claude에 프로젝트를 만든 뒤 과제 개요, 과제 기술서, 베이스라인 README 등을 넣고 물어봤다.
과제 참여 방법
물론이죠. 이 과제에 참여하기 위한 단계별 접근 방법을 설명해 드리겠습니다:
1. 환경 설정:
- Python 환경을 설정합니다.
- PyTorch와 Transformers 라이브러리를 설치합니다.
- CUDA가 설치된 GPU가 있는지 확인합니다.
2. 데이터 이해:
- 제공된 데이터셋을 다운로드하고 구조를 파악합니다.
- 데이터 형식을 이해하고, 어떻게 모델 입력으로 변환할지 생각합니다.
3. 베이스라인 모델 실행:
- 제공된 GitHub 저장소를 클론합니다.
- README에 있는 지침에 따라 베이스라인 모델을 실행해 봅니다.
- 학습과 추론 과정을 이해합니다.
4. 모델 선택 및 최적화:
- 베이스라인 모델(Bllossom)을 사용하거나 다른 한국어 언어 모델을 선택합니다.
- 모델 아키텍처를 이해하고 필요한 경우 수정합니다.
5. 데이터 전처리:
- src/data.py 파일을 참고하여 데이터 전처리 방식을 이해합니다.
- 필요한 경우 전처리 과정을 개선합니다.
6. 모델 학습:
- run/train.py 스크립트를 사용하여 모델을 학습시킵니다.
- 하이퍼파라미터를 조정하며 성능을 개선합니다.
7. 평가 및 개선:
- run/test.py를 사용하여 모델을 평가합니다.
- 결과를 분석하고 오류 케이스를 파악합니다.
- 모델이나 학습 과정을 개선할 방법을 찾습니다.
8. 반복:
- 4-7단계를 반복하며 모델 성능을 지속적으로 개선합니다.
9. 제출 준비:
- 최종 모델을 선택하고 제출 형식에 맞게 결과를 생성합니다.
- 필요한 문서와 코드를 정리합니다.
10. 제출 및 발표 준비:
- 결과를 제출하고, 상위권에 들 경우 발표를 준비합니다.
각 단계에 대해 더 자세한 설명이 필요하다면 말씀해 주세요. 어떤 부분부터 시작하고 싶으신가요?
코드 분석
네, 두 파일을 살펴보겠습니다. 각 파일의 주요 기능과 구조를 설명해 드리겠습니다.
1. train.py:
이 파일은 모델 학습을 위한 메인 스크립트입니다.
주요 기능:
- 명령줄 인자 파싱: argparse를 사용하여 학습에 필요한 파라미터를 받습니다.
- 모델 및 토크나이저 로드: AutoModelForCausalLM과 AutoTokenizer를 사용합니다.
- 데이터셋 준비: CustomDataset 클래스를 사용하여 학습 및 검증 데이터를 로드합니다.
- 학습 설정: SFTConfig를 사용하여 학습 파라미터를 설정합니다.
- 학습 실행: SFTTrainer를 사용하여 모델을 학습시킵니다.
주요 포인트:
- bfloat16 precision을 사용하여 학습 속도와 메모리 효율성을 개선합니다.
- 코사인 학습률 스케줄러를 사용합니다.
- 그래디언트 체크포인팅을 사용하여 메모리 사용량을 줄입니다.
2. data.py:
이 파일은 데이터 처리와 관련된 클래스들을 포함합니다.
주요 클래스:
a) CustomDataset:
- JSON 파일에서 데이터를 로드하고 처리합니다.
- 대화 내용을 특정 형식으로 포맷팅합니다.
- 입력 데이터와 레이블을 토큰화하고 인코딩합니다.
b) DataCollatorForSupervisedDataset:
- 배치 처리를 위한 데이터 콜레이터입니다.
- 입력 시퀀스를 패딩하고 어텐션 마스크를 생성합니다.
주요 포인트:
- 시스템 프롬프트를 사용하여 모델의 역할을 정의합니다.
- 대화 내용을 구조화된 형식으로 변환합니다.
- 레이블을 특정 포맷(A, B, C 옵션)으로 인코딩합니다.
이 두 파일은 함께 작동하여 대화 맥락 추론 태스크를 위한 모델을 학습시킵니다. train.py에서 CustomDataset을 사용하여 데이터를 로드하고, DataCollatorForSupervisedDataset을 사용하여 배치 처리를 수행합니다. 그리고 이를 SFTTrainer에 제공하여 모델을 학습시킵니다.
이 구조는 효율적인 데이터 처리와 모델 학습을 가능하게 하며, 특히 한국어 대화 맥락 추론 태스크에 맞춤화되어 있습니다.
인코딩 문제 해결
이 오류는 파일 인코딩 문제로 인해 발생한 것 같습니다. Windows에서 기본적으로 사용하는 'cp949' 인코딩으로 UTF-8로 인코딩된 한국어 파일을 읽으려고 해서 생긴 문제입니다. 이 문제를 해결하기 위해 다음과 같이 코드를 수정해 보세요:
1. `src/data.py` 파일에서 `CustomDataset` 클래스의 `__init__` 메소드를 다음과 같이 수정합니다:
```python
def __init__(self, fname, tokenizer):
IGNORE_INDEX=-100
self.inp = []
self.trg = []
self.label = []
PROMPT = '''You are a helpful AI assistant. Please answer the user's questions kindly. 당신은 유능한 AI 어시스턴트 입니다. 사용자의 질문에 대해 친절하게 답변해주세요.'''
answer_dict = {
"": None,
"inference_1": 0,
"inference_2": 1,
"inference_3": 2
}
with open(fname, "r", encoding="utf-8") as f: # 여기를 수정
data = json.load(f)
# 나머지 코드는 그대로 유지
```
이렇게 수정하면 파일을 UTF-8 인코딩으로 명시적으로 읽게 되어 인코딩 문제를 해결할 수 있습니다.
2. 만약 위의 방법으로도 문제가 해결되지 않는다면, 파일 자체의 인코딩을 확인해 볼 필요가 있습니다. UTF-8 with BOM으로 저장되었을 수 있습니다. 이 경우 다음과 같이 수정해 보세요:
```python
import codecs
def __init__(self, fname, tokenizer):
# ... (이전 코드 유지)
with codecs.open(fname, "r", encoding="utf-8-sig") as f: # UTF-8 with BOM 처리
data = json.load(f)
# ... (나머지 코드 유지)
```
3. 파일 경로가 올바른지 확인하세요. Windows에서는 경로 구분자로 '/'대신 '\'를 사용하는 것이 좋습니다. 아니면 raw 문자열을 사용할 수 있습니다:
```python
train_dataset = CustomDataset(r"resource\data\대화맥락추론_train.json", tokenizer)
```
4. 추가로, Windows 환경에서 긴 파일 경로를 처리하기 위해 다음과 같이 코드를 추가할 수 있습니다:
```python
import os
os.environ['PATH'] = os.environ['PATH'] + ';' + os.path.dirname(os.path.abspath(__file__))
```
이 코드를 `train.py` 파일의 맨 위에 추가하세요.
이러한 변경사항을 적용한 후 다시 실행해 보세요. 여전히 문제가 발생한다면, 오류 메시지를 공유해 주시면 추가적인 도움을 드리겠습니다.
메모리 부족 문제
이 오류 메시지는 CUDA(GPU 컴퓨팅을 위한 NVIDIA의 병렬 컴퓨팅 플랫폼)가 메모리 부족으로 인해 요청된 메모리를 할당할 수 없다는 것을 나타냅니다. 구체적으로:
1. "CUDA out of memory": GPU의 메모리(VRAM)가 모두 사용 중이라는 의미입니다.
2. "Tried to allocate 112.00 MiB": 프로그램이 추가로 112 메가바이트의 메모리를 할당하려고 시도했지만 실패했다는 뜻입니다.
이 오류가 발생하는 주요 원인들:
1. 모델 크기: 사용 중인 모델이 GPU 메모리에 비해 너무 큽니다.
2. 배치 크기: 한 번에 처리하는 데이터의 양이 너무 많습니다.
3. 중간 결과 저장: 학습 과정에서 중간 결과나 그래디언트를 저장하는 데 많은 메모리를 사용하고 있습니다.
4. 다른 프로세스: 다른 프로그램이 이미 GPU 메모리의 일부를 사용 중일 수 있습니다.
5. 메모리 누수: 코드에 메모리 누수가 있을 수 있습니다.
RTX 4090이 24GB의 VRAM을 가지고 있음에도 이런 오류가 발생한다는 것은 모델이 예상보다 더 많은 메모리를 사용하고 있거나, 메모리 관리에 문제가 있을 수 있다는 것을 시사합니다.
이 문제를 해결하기 위해서는 앞서 제안한 메모리 최적화 기법들(그래디언트 체크포인팅, 모델 양자화, 배치 크기 조정 등)을 적용해 볼 필요가 있습니다. 또한, 베이스라인 모델의 원래 구현에서 사용된 메모리 관리 기법들을 정확히 따랐는지 다시 한 번 확인해보는 것이 좋겠습니다.
FAQ 검토
네, FAQ를 제공해 주셔서 감사합니다. FAQ의 내용을 검토해 보니 몇 가지 중요한 점들이 있습니다:
1. 데이터 증강:
- (나) 유형의 경우 시험(test) 데이터를 제외한 모든 방식의 데이터 증강이 허용됩니다.
- 하지만 현재 우리는 (가) 유형을 다루고 있으므로, 데이터 증강은 허용되지 않습니다.
2. 모델 사용:
- 베이스라인 이외의 다른 모델을 사용해도 됩니다.
- 단, (가) 유형에서는 외부 데이터 사용 또는 데이터 증강이 허용되지 않습니다.
- 대회 시작 전에 공개된 모델은 모두 사용 가능합니다.
3. 하드웨어 제한:
- RTX 4090 24GB 환경에서 구동 가능해야 합니다.
- 학습은 더 높은 사양에서 진행해도 되지만, 추론 시에는 이 제한을 지켜야 합니다.
4. 평가:
- 시험 데이터의 모범 답안은 공개되지 않습니다.
- 정확한 성능 평가는 제출 후 대회 플랫폼에서 확인해야 합니다.
이 정보를 바탕으로, 현재의 접근 방식(베이스라인 모델 사용 및 result.json 제출)이 적절해 보입니다. 추가적인 개선을 위해서는 다음과 같은 방향을 고려해볼 수 있습니다:
1. 모델 선택:
- 다른 사전 학습된 모델을 시도해볼 수 있습니다. 단, 7월 이전에 공개된 모델을 사용하는 것이 안전합니다.
2. 하이퍼파라미터 튜닝:
- 학습률, 배치 크기, 에폭 수 등을 조정해볼 수 있습니다.
3. 모델 아키텍처 수정:
- 기본 모델 구조를 유지하면서 일부 레이어를 수정하거나 추가할 수 있습니다.
4. 입력 형식 최적화:
- 데이터 증강은 불가하지만, 입력 데이터의 형식을 최적화하는 것은 가능합니다.
5. 앙상블 기법:
- 여러 모델의 예측을 결합하는 방법을 고려해볼 수 있습니다.
현재로서는 result.json을 제출하고 공식 점수를 확인하는 것이 좋겠습니다. 그 후 점수에 따라 추가적인 개선 방향을 결정할 수 있을 것입니다.
제출
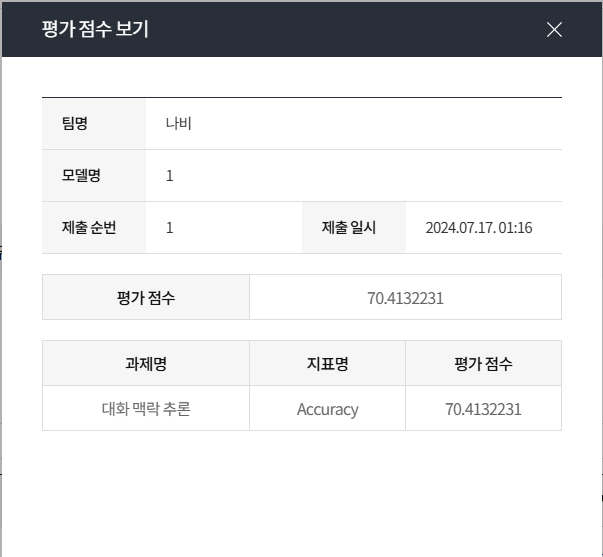
우선 베이스라인 코드를 그대로 실행해서 제출하는 것을 1차 목표로 삼고 이리저리 시도해서 겨우 해냈다.
'공모전' 카테고리의 다른 글
| 말평 4일차 (2) | 2024.07.19 |
|---|---|
| 말평 3일차 (0) | 2024.07.18 |
| 말평 2일차 (1) | 2024.07.17 |
| 인문사회통합성과확산센터 2024 아이디어 공모전 입상 (2) | 2024.06.19 |