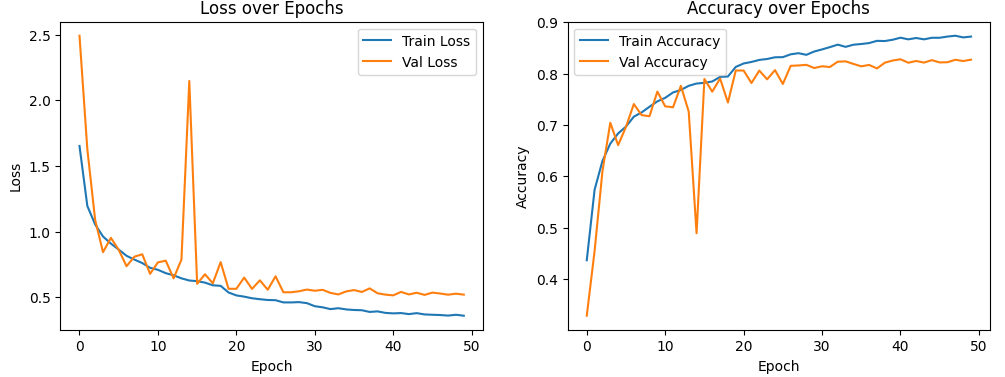
지난 글에서 CIFAR-10 이미지를 분류하는 CNN 모델의 정확도를 개선하기 위해 코드를 어떻게 수정했는지 설명했다. 수정한 코드와 실행 결과는 다음 주소에 있다.https://colab.research.google.com/drive/1XLw8fH57q8cm7mivzMVrxcprjU0lRw_b?usp=sharing 이번 글에서는 수정 전후 성능을 비교하고 변경 사항이 어떻게 성능 향상에 기여했는지 분석하겠다.1. 성능 비교수정 전 모델 (conv2):최종 검증 정확도: 약 63%학습 에포크 수: 20모델 구조:합성곱 레이어 1개 (필터 수: 10)MaxPooling2D 1개Flatten 레이어Dropout 레이어 (비율: 0.5)Dense 레이어 2개 (뉴런 수: 100, 10)수정된 모델:최종 검증 ..