지난 글에서 CIFAR-10 이미지를 분류하는 CNN 모델의 정확도를 개선하기 위해 코드를 어떻게 수정했는지 설명했다.
수정한 코드와 실행 결과는 다음 주소에 있다.
https://colab.research.google.com/drive/1XLw8fH57q8cm7mivzMVrxcprjU0lRw_b?usp=sharing
이번 글에서는 수정 전후 성능을 비교하고 변경 사항이 어떻게 성능 향상에 기여했는지 분석하겠다.
1. 성능 비교
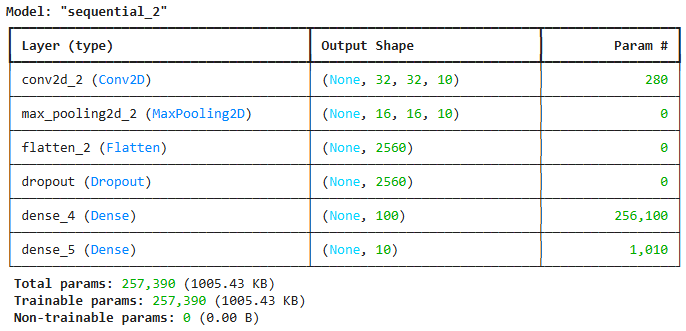
수정 전 모델 (conv2):
- 최종 검증 정확도: 약 63%
- 학습 에포크 수: 20
- 모델 구조:
- 합성곱 레이어 1개 (필터 수: 10)
- MaxPooling2D 1개
- Flatten 레이어
- Dropout 레이어 (비율: 0.5)
- Dense 레이어 2개 (뉴런 수: 100, 10)
수정된 모델:
- 최종 검증 정확도: 약 82.80%
- 학습 에포크 수: 50
- 모델 구조:
- 합성곱 레이어 3개 (필터 수: 32, 64, 128)
- 각 합성곱 레이어 뒤에 BatchNormalization 및 MaxPooling2D
- 각 풀링 레이어 뒤에 Dropout 레이어 (비율: 0.25)
- Flatten 레이어
- Dense 레이어 2개 (뉴런 수: 256, 10), 첫 번째 Dense 레이어 뒤에 BatchNormalization 및 Dropout (비율: 0.5)

성능 향상:
- 검증 정확도 증가: 약 20% 포인트 상승 (63% → 82.80%)
- 손실 감소: 검증 손실이 더 낮은 값으로 감소하여 모델의 예측 오류가 줄어들었다.
2. 변경 사항 및 그 영향
a. 모델 깊이와 필터 수 증가
변경 사항:
- 합성곱 레이어 수를 1개에서 3개로 늘렸다.
- 각 합성곱 레이어의 필터 수를 10개에서 32, 64, 128개로 증가시켰다.
의도 및 영향:
- 표현력 향상: 더 깊은 네트워크와 더 많은 필터를 통해 이미지의 다양한 특징과 복잡한 패턴을 더 잘 학습할 수 있다.
- 성능 개선: 모델의 표현력이 향상되어 정확도가 크게 상승했다.
b. 배치 정규화(Batch Normalization) 추가
변경 사항:
- 각 합성곱 레이어와 첫 번째 Dense 레이어 뒤에
BatchNormalization레이어를 추가했다.
의도 및 영향:
- 학습 안정화: 배치 정규화를 통해 각 층의 입력 분포를 정규화하여 학습을 안정화하고 수렴 속도를 높였다.
- 과적합 방지: 배치 정규화는 가중치 초기화에 덜 민감하게 만들어 과적합을 줄이는 데 도움이 된다.
- 성능 개선: 학습 과정이 안정적으로 진행되어 더 높은 정확도를 달성했다.
c. 드롭아웃(Dropout) 레이어 위치와 비율 조정
변경 사항:
- 드롭아웃 레이어를 합성곱 블록 뒤에 추가하고, 비율을 0.5에서 0.25로 조정했다.
- 첫 번째 Dense 레이어 뒤에 드롭아웃 비율을 0.5로 유지했다.
의도 및 영향:
- 과적합 방지 강화: 모델의 각 층에서 드롭아웃을 적용하여 뉴런의 공동 적합(co-adaptation)을 방지하고 일반화 능력을 향상시켰다.
- 성능 개선: 과적합을 줄여 검증 데이터에 대한 성능이 향상되었다.
d. Dense 레이어의 뉴런 수 증가
변경 사항:
- Dense 레이어의 뉴런 수를 100개에서 256개로 늘렸다.
의도 및 영향:
- 모델의 학습 능력 강화: 더 많은 뉴런을 통해 복잡한 데이터 패턴을 더욱 잘 학습할 수 있게 되었다.
- 성능 개선: 분류 능력이 향상되어 정확도가 상승했다.
e. 옵티마이저 및 학습률 조정
변경 사항:
- 옵티마이저를
Nadam에서Adam으로 변경하고, 학습률을1e-3으로 설정했다.
의도 및 영향:
- 학습 속도와 안정성 향상:
Adam옵티마이저는 모멘텀과 적응적 학습률을 결합하여 빠르고 안정적인 학습을 지원한다. - 성능 개선: 최적의 학습률을 통해 모델이 더 효과적으로 학습할 수 있었다.
f. 콜백 함수 적용
변경 사항:
EarlyStopping과ReduceLROnPlateau콜백을 추가했다.
의도 및 영향:
- 학습 최적화:
EarlyStopping: 검증 손실이 개선되지 않으면 학습을 조기에 중단하여 과적합을 방지한다.ReduceLROnPlateau: 검증 손실이 개선되지 않을 때 학습률을 감소시켜 더 세밀한 학습을 가능하게 한다.
- 성능 개선: 학습 과정을 동적으로 관리하여 최적의 모델을 얻었다.
g. 학습 에포크 수 증가
변경 사항:
- 학습 에포크 수를 20에서 50으로 증가시켰다.
의도 및 영향:
- 충분한 학습 기회 제공: 더 많은 에포크 동안 학습하여 모델이 데이터에 충분히 적합할 수 있도록 했다.
- 성능 개선: 에포크 수 증가와 콜백의 조합으로 최적의 성능을 달성했다.
h. 데이터 전처리 개선
변경 사항:
- 데이터의
reshape과정을 제거하고, 이미지를 단순히255.0으로 나누어 정규화했다.
의도 및 영향:
- 코드 간소화 및 효율성 향상: 불필요한 데이터 변환을 제거하여 코드의 효율성을 높였다.
- 성능에 미치는 영향은 미미하지만 코드의 가독성과 유지보수성이 향상되었다.
3. 결과 분석
학습 곡선 비교
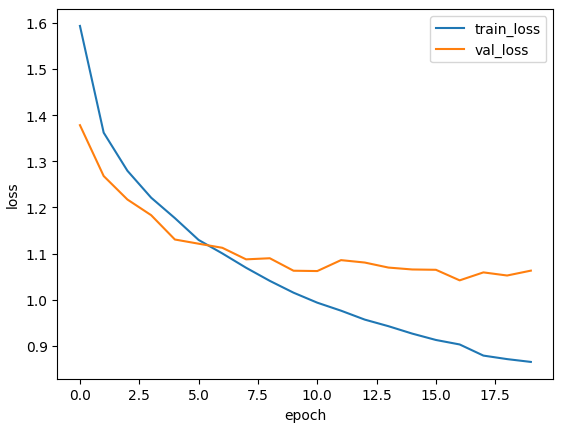
- 수정 전 모델:
- 학습 정확도와 검증 정확도가 에포크가 진행됨에 따라 서서히 증가하지만, 60% 초반에서 정체되었다.
- 검증 손실이 학습 손실에 비해 크게 감소하지 않고, 일정 수준에서 머무르고 있다.
- 이는 모델의 복잡도가 부족하여 데이터의 복잡한 패턴을 충분히 학습하지 못했기 때문으로 보인다.

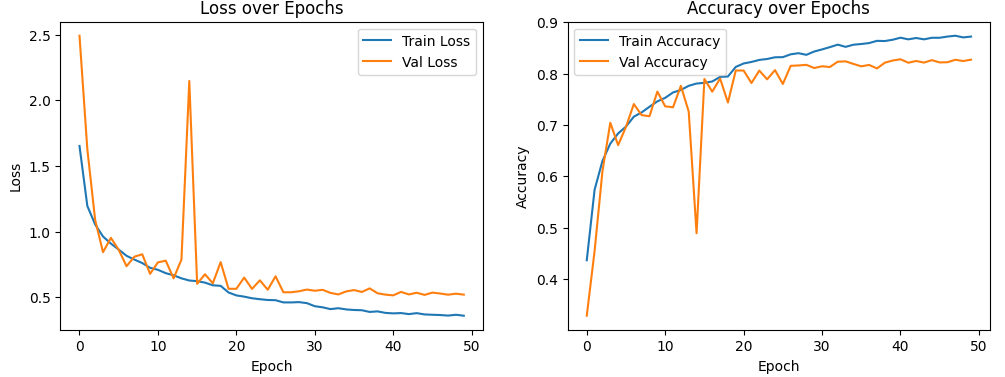
- 수정된 모델:
- 학습 정확도와 검증 정확도가 에포크가 진행됨에 따라 꾸준히 증가하여 80% 이상에 도달했다.
- 학습 손실과 검증 손실이 모두 감소하여 모델이 데이터를 효과적으로 학습하고 있음을 보여준다.
- 콜백을 통해 학습률이 조정되고, 과적합 없이 안정적인 학습이 이루어졌다.
모델 복잡도와 성능의 관계
- 모델 파라미터 수 증가:
- 수정 전 모델: 파라미터 수가 적어 모델의 표현력이 제한되었다.
- 수정된 모델: 파라미터 수가 증가하여 더 복잡한 패턴을 학습할 수 있게 되었다.
- 성능 향상:
- 모델의 복잡도가 증가함에 따라 데이터의 다양한 특징을 학습하여 성능이 향상되었다.
- 그러나 지나친 복잡도 증가는 과적합을 초래할 수 있으므로, 정규화 기법과 콜백을 통해 이를 방지했다.
4. 추가적인 개선 방안
이미 상당한 성능 향상을 이루었지만, 더 나은 성능을 위해 다음과 같은 방법을 고려할 수 있다.
- a. 데이터 증강(Data Augmentation) 적용: 데이터 증강을 통해 모델이 다양한 데이터 패턴에 노출되어 일반화 성능을 높일 수 있다.
- b. 학습률 스케줄링: 학습률을 수동으로 조정하여 학습 초기에는 큰 학습률로 빠르게 수렴하고, 후반에는 작은 학습률로 미세 조정한다.
- c. 모델 아키텍처 튜닝: 합성곱 레이어의 필터 수나 커널 크기 등을 조정하여 모델의 성능을 최적화한다.
- 필터 수를 조정하여 모델의 복잡도를 변화시킨다.
- 커널 크기를 변경하여 다양한 범위의 특징을 학습한다.
- d. 앙상블 기법 사용: 여러 모델의 예측을 결합하여 일반화 성능을 향상시킨다.
- 서로 다른 초기화나 아키텍처를 가진 여러 모델을 학습시킨 후, 예측 결과를 평균하거나 다수결 투표를 통해 최종 예측을 결정한다.
- e. 정규화 기법 추가: 과적합을 더욱 방지하고 모델의 일반화 성능을 높인다.
- L1 또는 L2 정규화를 적용하여 가중치의 크기를 제한한다.
5. 결론
- 변경 사항의 긍정적 영향 확인: 모델 구조의 개선과 학습 과정의 최적화가 성능 향상에 크게 기여했다.
- 성능 향상 정도: 검증 정확도가 약 63%에서 82.80%로 약 20% 포인트 상승했다.
- 추가 개선 가능성: 데이터 증강, 학습률 조정, 모델 튜닝 등을 통해 더욱 높은 성능을 달성할 수 있다.
6. 요약
- 모델 구조 개선: 더 깊고 복잡한 모델이 데이터의 복잡한 패턴을 효과적으로 학습하여 성능이 향상되었다.
- 정규화 및 규제 기법 적용: 배치 정규화와 드롭아웃을 통해 학습을 안정화하고 과적합을 방지했다.
- 학습 과정 최적화: 옵티마이저 선택, 학습률 조정, 콜백 함수 사용으로 학습 효율성을 높였다.